

过去一周,DeepSeek连续开(kāi)放(fàng)了(le)5个(gè)Infra项(xiàng)目(mù)的(de)源(yuán)代(dài)码(mǎ),正(zhèng)当(dāng)大(dà)家(jiā)以(yǐ)为(wèi)这(zhè)场(chǎng)开(kāi)源(yuán)盛(shèng)宴(yàn)已(yǐ)经(jīng)结(jié)束(shù)。3月(yuè)1日(rì),DeepSeek的(de)彩(cǎi)蛋(dàn)来(lái)了(le)!开(kāi)源(yuán)周(zhōu)Day6,DeepSeek官(guān)方(fāng)团(tuán)队(duì)在(zài)开(kāi)发(fā)者(zhě)社(shè)区(qū)Github和(hé)知(zhī)乎(hu)给(gěi)出(chū)了(le)DeepSeek-V3/R1推(tuī)理(lǐ)系(xì)统的技术解读。通过优化吞吐和延迟,DeepSeek理论上一天的总收入达到了562027美元,成本利润率为545%。
敏锐的网友——如MenloVentures投资人Deedy翻译了这意味着什么:“理论ARR(年收入)2亿美元、利润率超过500%,这样的商业效率理应是一家值100亿美元的公司。”

从2024年5月发布DeepSeekV2以来,DeepSeek模型服务就以“价格屠夫”示众,总是比行业其他模型便宜1/10左右,质疑DeepSeek亏本打价格战的声音也一直有。
通过这5天开放源代码以及今天的推理系统概述,这一疑虑也被打消,可以预见,模型推理价格越来越负担得起,且服务提供方也有的赚。这一事件的影响也可以通过社交平台网友展现出刷屏的惊喜得以一窥,“成本利润率545%,等于说你是在告诉我,我被Open AI抢劫了?开源周Day7的彩蛋是 AGI?”
但更大的信号指向生态伙伴,部署DeepSeek有的赚。
一位AI领域的投资人表示,“官方技术解读表明,云平台和上下游通过部署DeepSeek的服务,理论上收益和利润率可以达到很高”。无论是对于提供在线推理、还是私有化部署等服务的供应商,都是利好。
在这波DeepSeek热中受益的云平台硅基流动创始人袁进辉也在第一时间发表了自己的感受,“DeepSeek官方披露大规模部署成本和收益,又一次颠覆了很多人认知。”但需要时间适配DeepSeek V3/R1模型架构,他表示“现在很多供应商还做不到这个水平,主要是V3/R1架构和其它主流模型差别太大了,由大量小专家组成,导致瞄(miáo)准(zhǔn)其(qí)它主流模型结构开发的系统都不再有效,必须按照DeepSeek报告描述的方法才能达到最好的效率,而开发这样的系统难度很高,需要时间”。
袁进辉进一步指出现在复现这样的推理服务的难度以及DeepSeek可能的战略思考,“幸好这周DeepSeek五连发已经把主要模块开源出来了,降低了社区复现的难度。这些成果充分体现了DeepSeek团队第一性原理的思考方式和强悍的意志,他们应该是首先是基于某些原因想到了用这样的模型结构,然后发现这样的结构无论是训练还是推理,要做好都有非常大的工程挑战,不过这些问题在他们工程团队来说并不是搞不定的,关键是花那么大力气做完是否有大的收益呢,在最终结果出来前,谁也说不准(zhǔn),他(tā)们(men)还(hái)是(shì)赌(dǔ)了(le),结(jié)果(guǒ)是(shì)赌(dǔ)对(duì)了(le)。也(yě)可(kě)能(néng)是(shì)反(fǎn)过(guò)来(lái)的(de),基(jī)于(yú)系(xì)统(tǒng)的(de)出(chū)发(fā)点(diǎn)设(shè)计(jì)了(le)这(zhè)样(yàng)一(yī)个(gè)全新(xīn)的(de)模(mó)型(xíng)结构。”
在DeepSeek官(guān)方(fāng)报(bào)告(gào)中(zhōng)也(yě)提(tí)示(shì)了(le)DeepSeek-V3/R1推(tuī)理(lǐ)系(xì)统(tǒng)的(de)优(yōu)化(huà)目(mù)标(biāo)是(shì):更(gèng)大(dà)的(de)吞(tūn)吐(tǔ),更(gèng)低(dī)的(de)延(yán)迟(chí)。配(pèi)合(hé)技(jì)术(shù)解(jiě)读(dú),DeepSeek开(kāi)源(yuán)周(zhōu)放(fàng)出(chū)的(de)5个(gè)代(dài)码(mǎ)库(kù)带(dài)来(lái)的(de)影(yǐng)响(xiǎng)力(lì)才(cái)刚(gāng)刚(gāng)开(kāi)始(shǐ)。
《DeepSeek-V3 / R1 推(tuī)理(lǐ)系(xì)统(tǒng)概(gài)览(lǎn)全文
DeepSeek-V3/R1推(tuī)理(lǐ)系(xì)统(tǒng)的(de)优(yōu)化(huà)目(mù)标(biāo)是(shì):更(gèng)大(dà)的(de)吞(tūn)吐(tǔ),更(gèng)低(dī)的(de)延(yán)迟(chí)。
为(wèi)了(le)实(shí)现(xiàn)这(zhè)两(liǎng)个(gè)目(mù)标(biāo),我(wǒ)们(men)的(de)方(fāng)案(àn)是(shì)使(shǐ)用(yòng)大(dà)规(guī)模(mó)跨(kuà)节(jié)点(diǎn)专(zhuān)家(jiā)并(bìng)行(xíng)(Expert Parallelism / EP)。首(shǒu)先EP使得batch size大大增加,从而提高GPU矩阵乘法的效率,提高吞吐。其次EP使得专家分散在不同的 GPU上,每个GPU只需要计算很少的专家(因此更少的访存需求),从而降低延迟。
但EP同时也增加了系统的复杂性。复杂性主要体现在两个方面:
EP引入跨节点的传输。为了优化吞吐,需要设计合适的计算流程使得传输和计算可以同步进行。
EP涉及多个节点,因此天然需要Data Parallelism(DP),不同的(de)DP之(zhī)间(jiān)需(xū)要(yào)进(jìn)行(xíng)负(fù)载(zài)均(jūn)衡(héng)。
因(yīn)此(cǐ),本(běn)文的(de)主要(yào)内(nèi)容(róng)是(shì)如(rú)何使用EP增大batch size,如何隐藏传输的耗时,如何进行负载均衡。
1、大规模跨节点专家并行(Expert Parallelism / EP)
由于DeepSeek-V3/R1的专家数量众多,并且每层256个专家中仅激活其中8个。模型的高度稀疏性决定了我们必须采用很大的overall batch size,才(cái)能(néng)给(gěi)每(měi)个(gè)专(zhuān)家(jiā)提(tí)供(gōng)足(zú)够(gòu)的(de)expert batch size,从(cóng)而(ér)实(shí)现(xiàn)更(gèng)大(dà)的(de)吞(tūn)吐(tǔ)、更(gèng)低(dī)的(de)延(yán)时(shí)。需(xū)要(yào)大(dà)规(guī)模(mó)跨(kuà)节(jié)点(diǎn)专(zhuān)家(jiā)并(bìng)行(xíng)(Expert Parallelism / EP)。
我(wǒ)们(men)采用(yòng)多(duō)机(jī)多(duō)卡(kǎ)间(jiān)的(de)专(zhuān)家(jiā)并(bìng)行(xíng)策(cè)略(è)来(lái)达(dá)到(dào)以(yǐ)下(xià)目(mù)的(de):
Prefill:路由(yóu)专(zhuān)家(jiā)EP32、MLA和(hé)共(gòng)享(xiǎng)专(zhuān)家(jiā)DP32,一(yī)个(gè)部(bù)署(shǔ)单(dān)元(yuán)是(shì)4节(jié)点(diǎn),32个(gè)冗(rǒng)余(yú)路由(yóu)专(zhuān)家(jiā),每(měi)张(zhāng)卡(kǎ)9个(gè)路由(yóu)专(zhuān)家(jiā)和(hé)1个(gè)共(gòng)享(xiǎng)专(zhuān)家(jiā)
Decode:路由(yóu)专(zhuān)家(jiā)EP144、MLA和(hé)共(gòng)享(xiǎng)专(zhuān)家(jiā)DP144,一(yī)个(gè)部(bù)署(shǔ)单(dān)元(yuán)是(shì)18节(jié)点(diǎn),32个(gè)冗(rǒng)余(yú)路由(yóu)专(zhuān)家,每张卡2个路由专家和1个共享专家
2、计算通信重叠
多机多卡的专家并行会引入比较大的通(tōng)信(xìn)开(kāi)销(xiāo),所(suǒ)以(yǐ)我(wǒ)们(men)使(shǐ)用(yòng)了(le)双(shuāng) batch重(zhòng)叠(dié)来(lái)掩(yǎn)盖(gài)通(tōng)信(xìn)开(kāi)销(xiāo),提(tí)高(gāo)整(zhěng)体(tǐ)吞(tūn)吐(tǔ)。
对(duì)于(yú)prefill阶(jiē)段(duàn),两(liǎng)个(gè)batch的(de)计(jì)算(suàn)和(hé)通(tōng)信(xìn)交(jiāo)错(cuò)进(jìn)行(xíng),一(yī)个(gè)batch在(zài)进(jìn)行(xíng)计(jì)算(suàn)的(de)时(shí)候(hou)可(kě)以(yǐ)去(qù)掩(yǎn)盖(gài)另(lìng)一(yī)个(gè)batch的(de)通(tōng)信(xìn)开(kāi)销(xiāo);
对(duì)于(yú)decode阶(jiē)段(duàn),不(bù)同(tóng)阶(jiē)段(duàn)的(de)执(zhí)行(xíng)时(shí)间(jiān)有(yǒu)所(suǒ)差别,所以我们把attention部分拆成了两个stage,共计 5 个stage的流水线来实现计算和通信的重叠。
关于更多双batch重叠的细节,可以参考我们的profiling数据的 GitHub仓库:https://github.com/deepseek-ai/profile-data。
3、尽可能地负载均衡
由于采用了很大规模的并行(包括数据并行和专家并行),如果某个GPU的计算或通信负载过重,将成为性能瓶颈,拖慢整个系统;同时其他GPU因为等待而空转,造成整体利用率下降。因此我们需要尽可能地为每个GPU分配均衡的计算负载、通信负载。
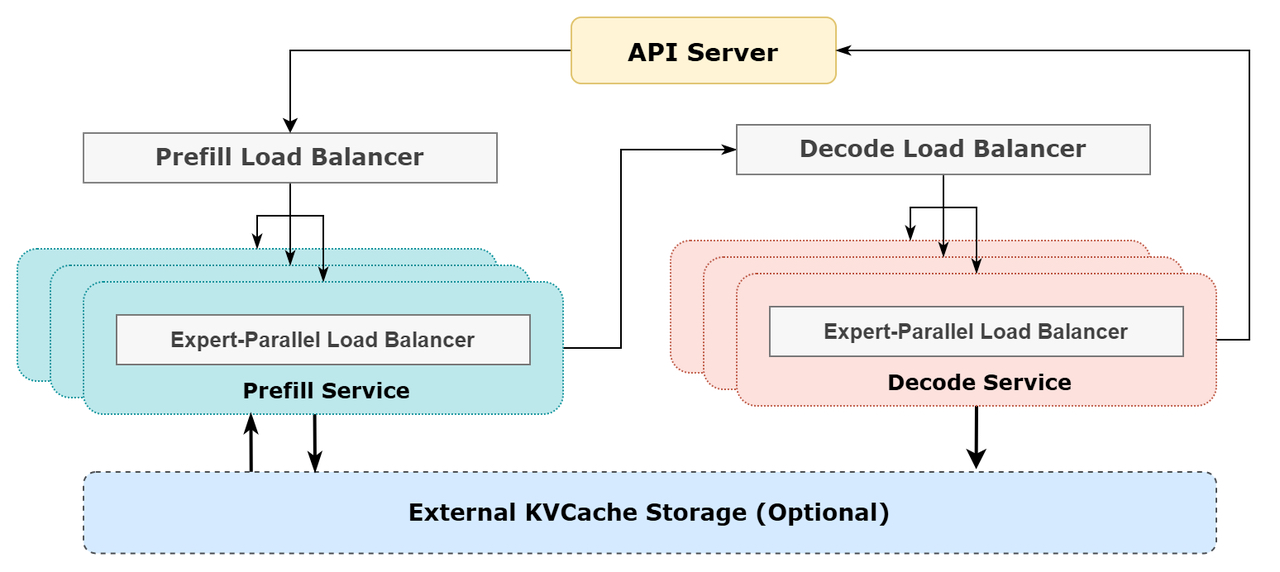
Prefill Load Balancer
核心问题:不同数据并行(DP)实例上的请求个数、长度不同,导致 core-attention 计算量、dispatch发送量也不同
优化目标:各GPU的计算量尽量相同(core-attention 计算负载均衡)、输入的token数量也尽量相同(dispatch发送量负载均衡),避免部分GPU处理时间过长
Decode Load Balancer
核心问题:不同数据并行(DP)实例上的请求数量、长度不同,导致core-attention计算量(与KVCache占用量相关)、dispatch发送量不同
优化目标:各GPU的KVCache占用量尽量相同(core-attention计算负载均衡)、请求数量尽量相同(dispatch 发送量负载均衡)
Expert-Parallel Load Balancer
核心问题:对于给定 、MoE模型,存在一些天然的高负载专家(expert),导致不同GPU的专家计算负载不均衡
优化目标:每个GPU上的专家计算量均衡(即最小化所有 GPU 的dispatch接收量的最大值)
4、参(cān)考(kǎo)架(jià)构(gòu)图(tú)
5、线(xiàn)上(shàng)系(xì)统(tǒng)的(de)实(shí)际(jì)统(tǒng)计(jì)数(shù)据(jù)
DeepSeek V3和(hé)R1的(de)所(suǒ)有(yǒu)服(fú)务(wu)均(jūn)使(shǐ)用(yòng)H800 GPU,使(shǐ)用(yòng)和(hé)训(xun)练(liàn)一(yī)致的精度,即矩阵计算和dispatch传(chuán)输(shū)采用(yòng)和训练一致的FP8格式,core-attention计算和combine传输采用和训练一致的BF16,最大程度保证了服务效果。
另外,由于白天的服务负荷高,晚上的服务负荷低,因此我们实现了一套机制,在白天负荷高的时候,用所有节点部署推理服务。晚上负荷低的时候,减少推理节点,以用来做研究和训练。在最近的24小时里(北京时间 2025/02/27 12:00 至 2025/02/28 12:00),DeepSeek V3和R1推理服务占用节点总和,峰值占用为278个节点,平均占用226.75个节点(每个节点为8个H800 GPU)。假定GPU租赁成本为2美元/小时,总成本为 $87072/天。
在24小时统计时段内,DeepSeek V3和R1:
输入token总数为608B,其中342B tokens(56.3%)命中 KVCache 硬盘缓存。
输出token总数为168B。平(píng)均输出速率为20~22tps,平均每输出一个token的KVCache长度是4989。
平均每台H800的吞吐量为:对于prefill任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于decode任务,输出吞吐约 14.8k tokens/s。
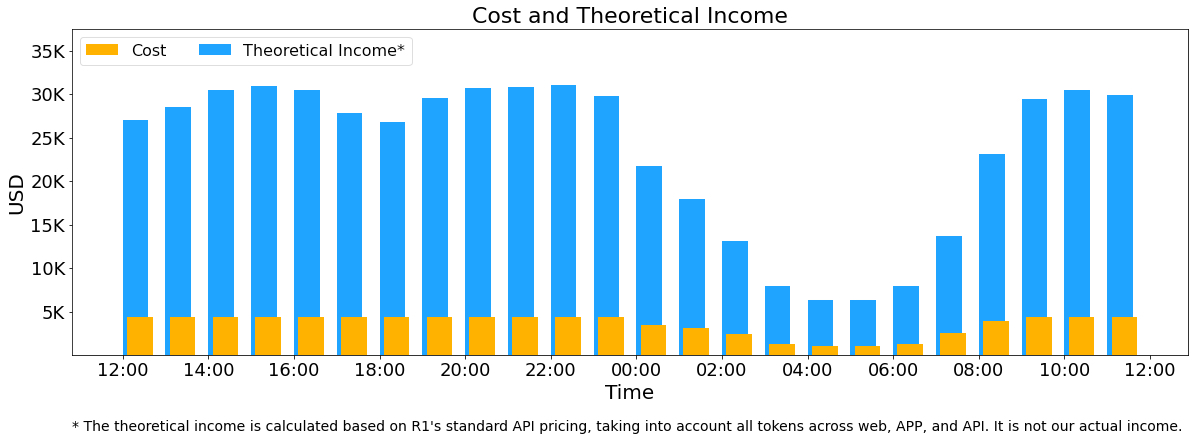
以上统计包括了(le)网(wǎng)页(yè)、APP 和(hé) API 的(de)所(suǒ)有(yǒu)负(fù)载(zài)。如(rú)果(guǒ)所(suǒ)有(yǒu)tokens全部(bù)按(àn)照(zhào)DeepSeek R1的(de)定(dìng)价(jià) (注(zhù):DeepSeek R1 的(de)定(dìng)价(jià):$0.14 / 百(bǎi)万(wàn)输(shū)入(rù)tokens (缓(huǎn)存(cún)命(mìng)中(zhōng)),$0.55 / 百(bǎi)万(wàn)输(shū)入(rù)tokens (缓(huǎn)存(cún)未(wèi)命(mìng)中(zhōng)),$2.19 / 百(bǎi)万(wàn)输(shū)出(chū) tokens;当(dāng)然(rán)我(wǒ)们(men)实(shí)际(jì)上(shàng)没(méi)有(yǒu)这(zhè)么(me)多(duō)收(shōu)入(rù),因(yīn)为(wèi)V3的(de)定(dìng)价(jià)更(gèng)低(dī),同(tóng)时(shí)收(shōu)费(fèi)服(fú)务(wu)只(zhǐ)占(zhàn)了(le)一(yī)部(bù)分(fēn),另(lìng)外(wài)夜(yè)间(jiān)还(hái)会(huì)有(yǒu)折(zhé)扣(kòu))计(jì)算(suàn),理(lǐ)论(lùn)上(shàng)一天的总收入为562027美元,成本利润率545%。