

【导语】6月17日,上海AI独角兽MiniMax宣布正式开源其推理模型MiniMax-M1(M1),标志着全球首个开放权重的大规模混合注意力推理模型问世。M1凭借创新技术,在性能与推理效率上取得突破,尤其在长上下文理解和代码生成方面表现出色。此外,M1在成本效益上展现优势,强化学习阶段成本相对较低。专家指出,MiniMax此举不仅填补了开源领域技术空白,更以“开源+场景化”策略推动国产大模型实用化进程,为市场竞争注入新活力。
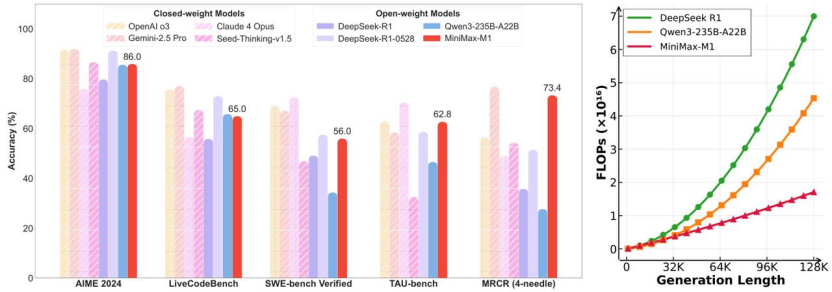
6月17日,上海AI独角兽MiniMax正式开源推理模型MiniMax-M1(以下简称“M1”)。MiniMax称,这是全球首个开放权重的大规模混合注意力推理模型。凭借混合门控专家架构(Mixture-of-Experts,MoE)与 Lightning Attention 的结合,M1在性能表现和推理效率方面实现了显著突破。实测数据显示,M1系列在长上下文理解、代码生成等生产力场景中超越多数闭(bì)源模型,仅微弱差距落后于顶尖闭源系统。
开源报告截图 来源:MiniMax提供
M1支持目前业内最高100万token上下文输入,同时支持最多8万token输出。成本表现方面,在进行8万Token的深度推理时,M1所需的算力仅为DeepSeek R1的约30%;生成10万token时,推理算力只需要DeepSeek R1的25%。MiniMax表示,M1整个强化学习阶段只用到512块H800三周时间,租赁成本为53.74万美元(yuán)。
天(tiān)使投资人、资深人工智能专家郭涛向澎湃科技(www.thepaper.cn)分析认为,目前国内大模型市场格局早已形成,大模型竞争不仅仅是技术的竞争,而是算力、数据、应用场景等整个生态的竞争。此次MiniMax更新填补了开源领域长上下文技术的空白,更以“开源+场景化”路径打破技术垄断,为国产大模型迈向实用化树立新标杆。