

“大模型能力越来越强,各类评测榜单层出不穷,模型分数越刷越高,但大模型的能力对我们个人来说究竟有什么用,我们并不知道。”2月22日,在2025全球开发者先(xiān)锋(fēng)大(dà)会(huì)“浦(pǔ)江(jiāng)AI生(shēng)态(tài)论(lùn)坛(tán)”上(shàng),上(shàng)海(hǎi)人(rén)工(gōng)智(zhì)能(néng)实(shí)验(yàn)室(shì)双(shuāng)聘(pìn)研(yán)究(jiū)员(yuán)、上(shàng)海(hǎi)交(jiāo)通(tōng)大(dà)学(xué)教(jiào)授(shòu)翟(dí)广(guǎng)涛(tāo)表(biǎo)示(shì),大(dà)模(mó)型(xíng)终(zhōng)究(jiū)要(yào)为(wèi)人(rén)服(fú)务(wu),当(dāng)前(qián)以(yǐ)模(mó)型(xíng)为(wèi)中(zhōng)心的先出题、再做题、算分的评价模式面临数据泄露和性能饱和两大挑战,大模型出现“高分低能”。
为了应对这种情况,上海人工智能实验室提出了“以人为本”的评测思路。上海人工智能实验室大模型开放评测平台司南正式发布“以人为本”(Human-Centric Eval)的大模型评测体系,系统评估大模型能力对人类社会的实际价值,为人工智能应用更贴近人类需求提供可量化的人本评估标注。
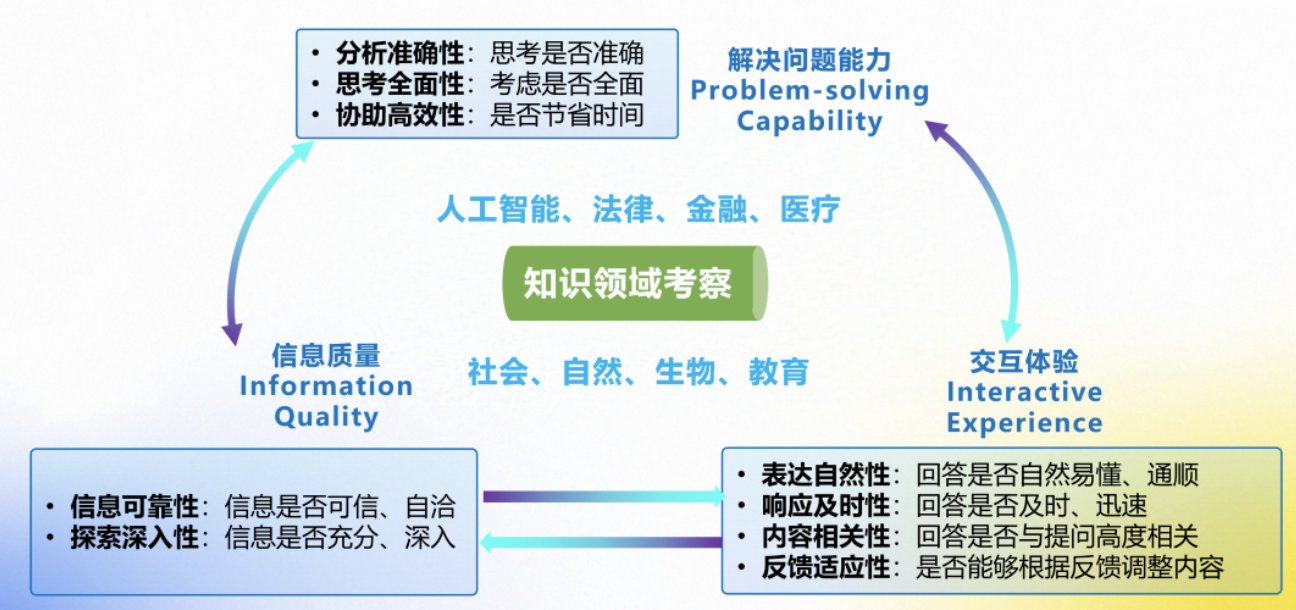
上(shàng)海(hǎi)人(rén)工(gōng)智(zhì)能(néng)实(shí)验(yàn)室(shì)提(tí)出(chū)“以(yǐ)人(rén)为(wèi)本(běn)”的(de)评(píng)测(cè)思(sī)路。
传(chuán)统(tǒng)大(dà)模(mó)型(xíng)基(jī)准(zhǔn)测(cè)试(shì)普(pǔ)遍(biàn)采用(yòng)结(jié)果(guǒ)导(dǎo)向(xiàng)的(de)评(píng)价标准,这种评价方式虽然能够直观反映模型性能,却忽略了人类实际需求。司南团队提出的评测方案根据人类(lèi)需求设计实际问题,让人与大模型协作解决,再由人类对模型的辅助能力进行主观评分,以此补充客观评价的不足,使评估更贴合人类感知。
其中,“认知科学驱动”评估框架围绕解决问题能力、信息质量、交互体验三大核心维度,构建覆盖多场景、多领域的主观评测体系。通过模拟学术研究、数据分析、决策支持等真实人类需求,由用户与大模型协作完成任务,并基于人类主观反馈量化评估模型的实际应用价值,为下一步技术研发与产业落地提供科学参考。
为了验证“以人为本”评估方式的有效性,同时评测大模型在研究生学术研究中的应用价值,司南团队选取了当前公认的优秀模型DeepSeek-R1、GPT-o3-mini、Grok-3作为评测对象,组织有学术研究需求的研究生参与。团队根据文献综述、数据分析、可行性研究等学术研究中的常见需求,设计了人工智能、法律、金融等8个领域的相关问题,研究生与大模型协作解决。实验结果显示,所有受测模型分析准确性、思考全面性、协助高效性维度能力均势。DeepSeek-R1在解决生物、教育学科问题上表现突出;Grok-3在金融、自然领(lǐng)域优势明显;GPT-o3-mini则在社会领域表现良好。